NoriRegressor is a scikit-learn estimator, it plugs directly into
shapiq — a fast SHAP implementation with
native Shapley-interaction support — and the rest of the sklearn interpretability
ecosystem. The helpers in synthefy_nori.interpretability are thin convenience
wrappers, so you can also use the underlying tools directly.
Runnable example
Install
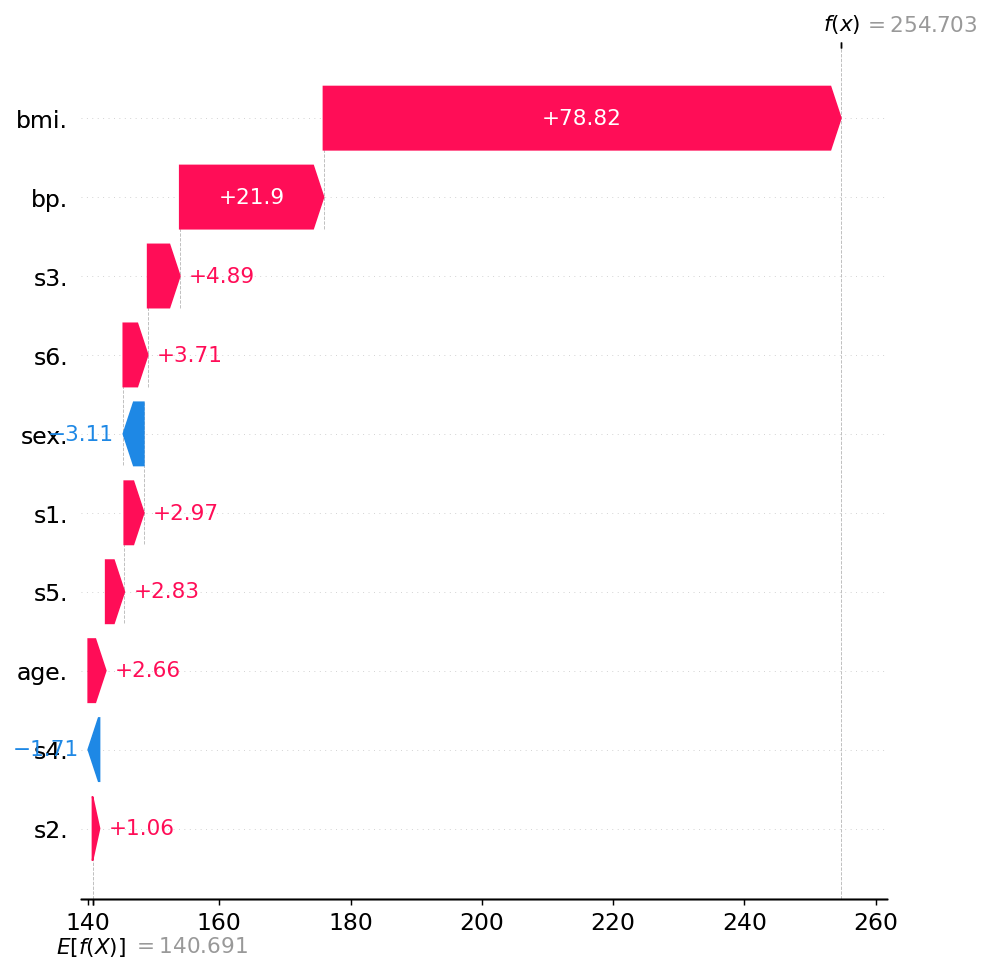
SHAP / Shapley values & interactions
get_nori_imputation_explainer builds a shapiq.TabularExplainer that removes
features by imputation against a background set. The training context stays
fixed across coalitions, so each coalition is a single predict call — the cost
is set by budget.
get_nori_imputation_explainer:
index—"SV"for plain Shapley values, or"k-SII"for k-Shapley interactions (max_order=1reduces it to standard Shapley values).max_order— maximum interaction order (1= single-feature attributions,2= pairwise interactions).imputer—"baseline"(one forward per coalition; recommended) or"marginal"/"conditional"(multi-sample, much slower).
Budget trades accuracy for cost. Start at
128 and raise only if the
explanation looks noisy: <10 features → 64–128; 10–20 → 128–512;
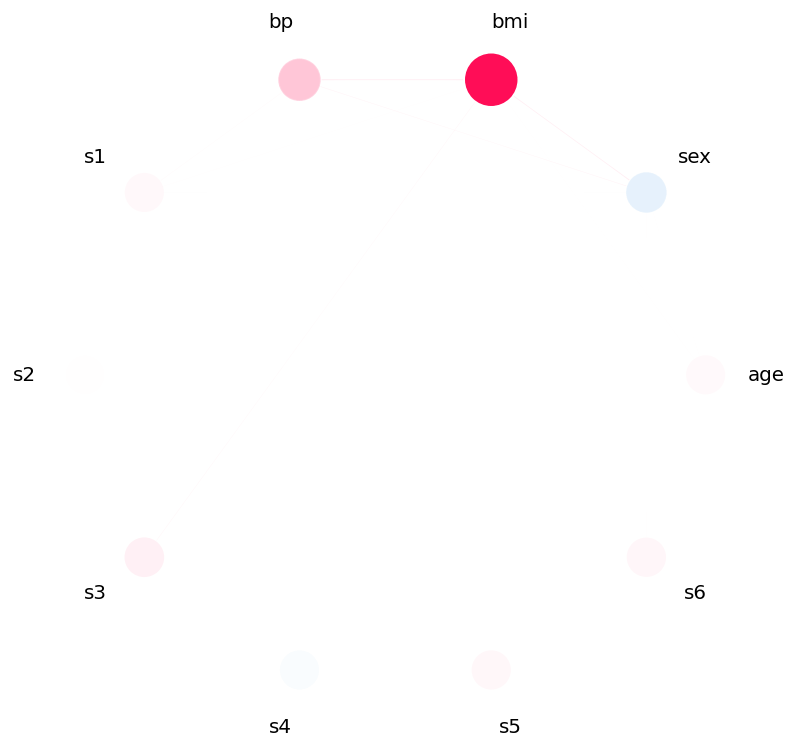
20+ → 512–2048.index="k-SII", max_order=2 the explainer also surfaces pairwise
interactions, which you can view as a network:
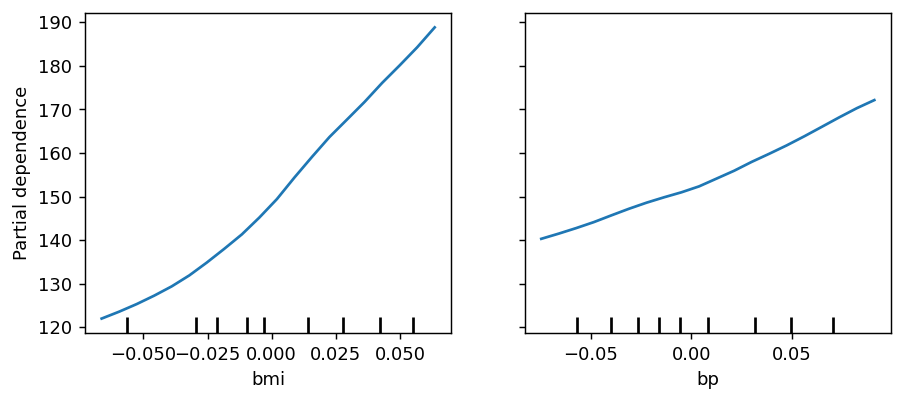
Partial dependence / ICE
A global view of how the prediction shifts across a feature’s range:(i, j) tuples in features for 2-D interaction surfaces. Returns an
sklearn PartialDependenceDisplay.
Feature selection
Find a minimal feature subset that preserves cross-validated performance (sequential selection):n_features_to_select accepts an int, a fraction, or "auto" (with tol). The
result also reports baseline-vs-selected CV scores.
Sequential selection re-fits Nori in-context on every CV split, so keep it to a
few thousand samples and a modest feature count.
Notes
- These run on the local Python package (
synthefy-nori), not the hosted API. - TabPFN’s fast Shapley path reuses a KV-cache across coalitions; Nori’s public package runs one forward per coalition — correct and budget-controlled, just not cache-accelerated.